Amazon S3 Metadata
Accelerate data discovery with near real-time object metadata
Object metadata in Amazon S3
Every object in Amazon S3 carries metadata that describes it. There are four types of object metadata in S3. System-defined metadata is automatically captured by S3 and includes properties such as an object's creation time, size, storage class, and encryption status. System-defined metadata is always present and maintained by S3. User-defined metadata consists of custom key-value pairs you set at upload time, such as a department name or project code. User-defined metadata is immutable after upload and limited in size. Object tags are key-value labels you can add, modify, or delete at any time. Tags integrate with IAM policies, lifecycle rules, cost allocation, and S3 analytics, making them ideal for access control and operational workflows. Annotations let you attach rich, large-scale business context to any object at any time. Annotations support formats like JSON, XML, and YAML, with up to 1 GB per object. Annotations are mutable, share the same durability and consistency as the object, and are managed through their own set of S3 APIs.
Surface, store, and query all your metadata in one place
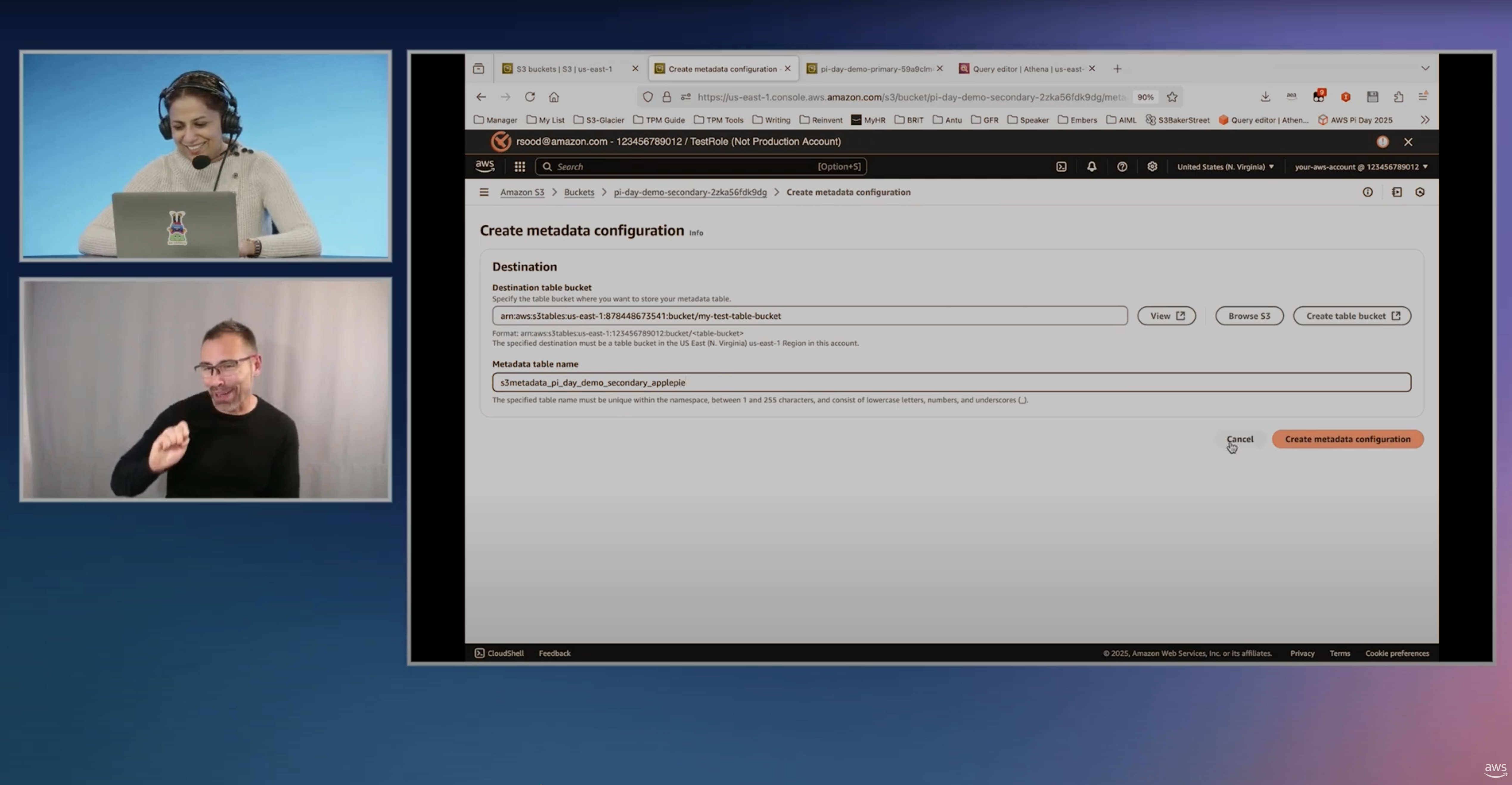
Amazon S3 Metadata brings all four types of object metadata together into a single, queryable experience. S3 Metadata automatically surfaces, stores, and queries metadata for objects in your S3 buckets, including system-defined details, user-defined metadata, object tags, and annotations, so you can find the data you need for business analytics, real-time inference applications, AI agents, and more.
S3 Metadata stores this information in fully managed, read-only Apache Iceberg tables that you can query with Amazon Athena and other Iceberg-compatible tools. S3 Metadata provides three table types: journal tables capture object-level events and annotation changes in near real-time, enabling event-driven workflows and change tracking. Live inventory tables provide a continuously updated view of all objects and their current metadata across your bucket. Annotation tables store annotations in a queryable format so you can search across all annotations at scale.
S3 Metadata automatically populates metadata for both new and existing objects, giving you a comprehensive, always-current view of your data without building or maintaining separate metadata systems. You can also use natural language to search objects by their metadata using agents in Amazon SageMaker Unified Studio, or any IDE with the S3 Tables MCP server.

Benefits
Designed to create and manage metadata for all objects in your S3 buckets (both existing objects and new uploads) providing a comprehensive view of your data.
Quickly find and retrieve the data you need across up to trillions of objects in S3. We update the metadata on an hourly basis so you can easily understand your latest storage landscape.
Attach up to 1GB of mutable metadata per object using annotations. Store AI-generated summaries, technical specifications, compliance details, or any contextual information, eliminating the need for separate metadata management systems.
Access your metadata through live inventory tables, journal tables, and annotation tables in managed S3 Tables, with built-in support for Apache Iceberg.
Analyze metadata using familiar AWS services like Amazon Athena, Redshift, and EMR through the S3 Tables integration with Amazon SageMaker lakehouse architecture. Query annotations using SQL or natural language through the Model Context Protocol (MCP) server. S3 Metadata is compatible with popular open source tools.
Use cases
Track and manage AI-generated videos, images, and documents with rich annotations including their origin, creation time, the AI model used with Amazon Bedrock, confidence scores, and processing lineage—all stored directly with your objects.
Use annotations to catalog all data with rich business context for easier discovery and utilization. Attach transcripts, scene descriptions, technical specifications, and licensing information directly to media files without separate databases.
Improve data organization and compliance by attaching regulatory metadata, audit trails, data lineage, and compliance status directly to objects. Query across petabytes to identify data subject to specific regulations or retention policies.
Analyze object metadata across your entire storage footprint to identify opportunities for cost savings and performance improvements.
Quickly identify and analyze relevant datasets for business intelligence and decision-making.
Customers
Cambridge Mobile Telematics
Cambridge Mobile Telematics (CMT) is the world’s largest telematics service provider. Its mission is to make the world’s roads and drivers safer. The company’s AI-driven platform, DriveWell Fusion®, gathers sensor data from millions of IoT devices — including smartphones, proprietary Tags, connected vehicles, dashcams, and third-party devices — and fuses them with contextual data to create a unified view of vehicle and driver behavior.
"At CMT, we store and analyze multiple petabytes of data from mobile IoT devices worldwide to enhance driver and road safety. As we scale, locating specific data for developing new insights and models becomes increasingly challenging. S3 Metadata, particularly its custom metadata capability, allows us to annotate all our data and maintain the metadata in a managed, queryable table. Now, finding relevant data requires just one efficient and cost-effective SQL query. This makes S3 Metadata a game-changer, enabling us to bring new capabilities to our customers."
Tim Vogel, Chief Information Officer – Cambridge Mobile Telematics
PayPal
PayPal has been revolutionizing commerce globally for more than 25 years. Creating innovative experiences that make moving money, selling, and shopping simple, personalized, and secure, PayPal empowers consumers and businesses in approximately 200 markets to join and thrive in the global economy.
"S3 Metadata provides us with a simple, straightforward mechanism to analyze trillions of S3 objects using standard tools like Amazon Athena and Amazon QuickSight. With this functionality, we can spend our time making decisions rather than building our complex data pipelines to access and query S3 object metadata."
Jon Southall, VP Engineering, Large Enterprise Platforms – PayPal

Roche
Roche is a biotech company that combines pharmaceuticals and diagnostics to achieve advances in personalized healthcare and improve people’s lives.
"S3 Metadata accelerates our generative AI initiatives. As we build LLM applications such as internal chatbots for our teams, unstructured data like PDFs are becoming increasingly valuable. We need to ingest lots of domain-specific documents to a Retrieval Augmented Generation (RAG) application so that the chatbot can tailor to Roche’s specific business contexts. However, this also means that we have more and more unstructured data that we need to manage. We need a metadata system to efficiently describe our unstructured data so that our users can quickly sift through our large data lake to identify the relevant datasets for the particular generative AI application that they are building. With S3 Metadata, building a robust metadata system has been simplified to a few clicks in the AWS Management Console. As we continuously ingest more unstructured data, S3 Metadata automatically surfaces the metadata and keeps the metadata up-to-date. We also employ our own Lambda to extract business-specific metadata, such as classifying documents based on a taxonomy relevant to Roche, and store this metadata in the same glue catalog alongside the S3 Metadata table so that with a simple SQL join we can have all the metadata we need. S3 Metadata helps us build generative AI applications faster, which allows us to focus on building rather than organizing our data."
Yannick Misteli, Head of Pharma Commercial Engineering – Roche
SmugMug / Flickr
SmugMug and Flickr provide online platforms where photographers can upload and share photos and videos. The company stores billions of photos and videos on its application.
"Photos uploaded to SmugMug and Flickr pass through a series of pipelines, where we run feature detection, metadata extraction, point of interest calculations, and in some instances face detection. Until now, all of that context lived in separate databases that we had to keep synchronized with hundreds of billions of objects in S3. With S3 annotations, we can attach all of the relevant data directly to the photo object at ingest time, in structured JSON, up to 1 MB per annotation. Our enrichment results now travel with the object through replication and cross-region transfers, and we can query across all of them at scale through annotation tables without building our own indexing layer. This is a fundamental simplification of how we connect intelligence to storage."
Erik Giberti, Sr. Director of Product & Engineering – SmugMug
"Imagine flying a time machine through your Amazon S3 data. At SmugMug and Flickr, we’ve stored over 22 years of our customers’ photos, hundreds of billions of objects, in S3. The new S3 Metadata feature helps us to easily explore our S3 object metadata easily and affordably, querying across metadata such as object size over time to understand how our data has evolved, which previously involved joining expensive database queries with object inventories. Understanding how our photographers use our storage helps further our commitment to build a better world through the power of photography."
Andrew Shieh, Principal Engineer – SmugMug
Atlan
Atlan is an active metadata platform and data management company that serves as the context layer for enterprise AI. It connects metadata, data lineage, and business logic into a unified graph, enabling AI agents and human teams to discover, understand, and trust enterprise data.
"Enterprises run AI agents everywhere, and those agents only succeed when they have trusted context to act on data correctly. Atlan automatically collects and enriches enterprise context across a customer's systems of record and data, including the objects in their S3 buckets, and we keep that context open to any agent through formats like Apache Iceberg and protocols like MCP. With Amazon S3 Metadata annotation tables, Atlan's context for S3 can be made available directly on the objects as an Iceberg-native annotation table, queryable through Amazon Athena and other Iceberg compatible tools— so an agent can read the data in S3 and its Atlan context together, wherever it runs."
Chandru Sugunan, Director of Product – Atlan
Nomad Media
Nomad Media is an AI-powered media asset management platform that helps organizations turn overlooked content libraries into strategic assets. Built on AWS’s enterprise-grade infrastructure, the platform combines intelligent content discovery, automated enrichment, and seamless integrations to give teams a smarter, simpler way to organize, find, and activate their media at any scale.
"Nomad Media automatically enriches every asset that enters our platform with AI-generated metadata including transcriptions, scene descriptors, object tags, and rights availability windows, and that intelligence is only valuable if it stays with the content it describes. As our customers' assets move across storage tiers, replicate across regions, and transition into deep archive, S3 annotations give us a native mechanism to keep that metadata bound directly to each object without building or maintaining synchronization logic on our side. The result is that the AI enrichment generated on day one travels with the asset for its entire lifecycle, exactly where intelligent media management requires it to be."
Adam Miller, CEO and Co-Founder – Nomad Media
RAZR
RAZR is a technology company that delivers intelligent, scalable rewards and loyalty solutions. We help businesses acquire, retain, and grow customers through our configurable technology that drives engagement and long-term value across industries.
"We're building a new file ingestion platform on Amazon S3, and tracking processing status across objects at scale was a core requirement from day one. With S3 annotations, we attach structured processing context directly to each object as it moves through our pipeline stage - no separate metadata system to build or keep in sync. We can then query that state at scale through Athena without schema migrations. Annotations persist through the object lifecycle and replicate automatically, so our team always knows exactly where any object stands. This is exactly the capability we needed to build this right from the start."
Liam Whelan, Director of Software Engineering – RAZR

Solink
Solink offers trusted cloud video security systems for businesses of all sizes. Its hardware and software help give visibility to IT, loss prevention, operations, and security teams at tens of thousands of locations in more than 40 countries.
"Solink processes over 500 million hours of video monthly, integrating security footage with critical business data from over 350 sources. AWS supports the infrastructure we rely on and Amazon S3 Metadata will take that further—delivering real-time insights that enhance our content management, from monitoring storage and usage to tracking real-time effects of customer configuration changes."
Martin Soukup, Chief Technical Officer – Solink
Commvault
Commvault is the gold standard in cyber resilience, helping more than 100,000 organizations keep data safe and businesses resilient and moving forward. Today, Commvault offers the only cyber resilience platform that combines the best data security and rapid recovery at enterprise scale across any workload, anywhere—at the lowest TCO.
"Amazon S3 has emerged as a leading cloud storage provider for various data types. Amazon S3 Metadata will enable vendors like Commvault to proactively help identify and safeguard sensitive information, while also helping to automate elements like data tiering, and enhance outcomes for our shared customers. S3 Metadata facilitates efficient data organization and helps streamline data discovery, allowing for detailed annotation of objects, which is crucial for cloud-first cyber resilience."
Pranay Ahlawat, Chief Technology and AI Officer – Commvault

New Relic
The New Relic Intelligent Observability Platform gives customers deep performance analytics for every part of your software environment. Customers can easily view and analyze massive amounts of data, and gain actionable insights in real-time.
"As a leader in observability, New Relic’s data engine processes approximately 1.3 exabytes of Amazon S3 data daily. S3 Metadata will accelerate our innovation by automatically generating rich object metadata, thereby simplifying data exploration needed by our teams to run product experiments and build proofs of concept, such as developing new metrics beneficial for our customers. S3 Metadata will reduce our effort to build and maintain a robust metadata system from hundreds of hours to just a few clicks in the S3 Management Console, enabling our engineers to focus on data analysis rather than data organization."
Siva Padisetty, Chief Technology Officer – New Relic
Resources for S3 Metadata
Accelerate data discovery with object metadata